UniTabBank Dataset
The UniTabBank dataset comprises a total of 55,443 document images, organized into four primary categories based on content and layout: Annual Report (55%), Book (21%), Magazine (17%), and Newspapers (5.3%). These document images are available in three formats: PDFs, photographed documents, and scanned documents. The dataset spans 28 languages, including Arabic, Assamese, Bengali, Bodo, Chinese, English, Farsi, French, Gujarati, Hindi, Indonesian, Japanese, Kannada, Korean, Malayalam, Manipuri, Marathi, Nepali, Oriya, Punjabi, Sanskrit, Sinhala, Spanish, Tamil, Telugu, Thai, Urdu, and Vietnamese. In total, the dataset contains 81,179 annotated table instances. Tables exhibit a wide variety of table layout structures, including (i) bordered tables with complete row and column separators, (ii) bordered tables without row and column separators, (iii) borderless tables with row and column separators, (iv) bordered tables with partial separators, (v) tables containing merged cells, and (vi) tables without merged cells.
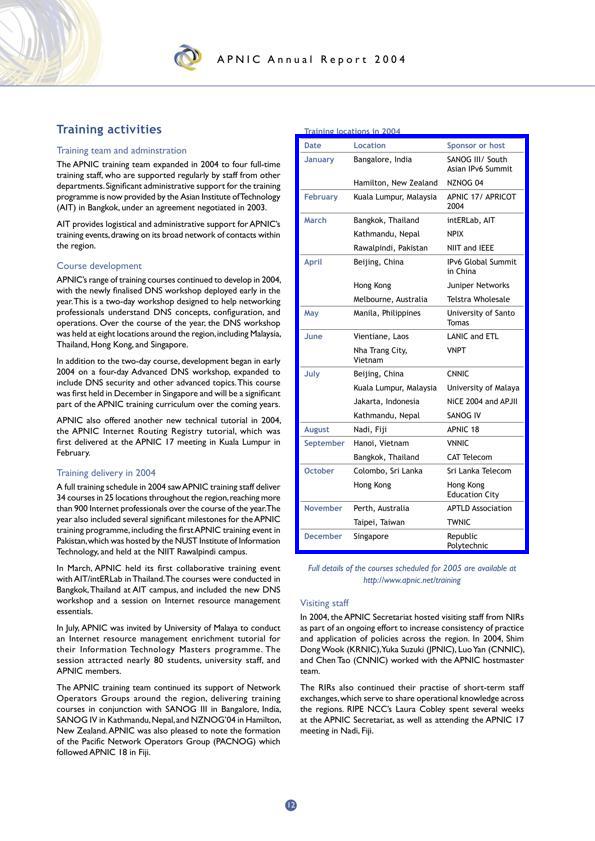
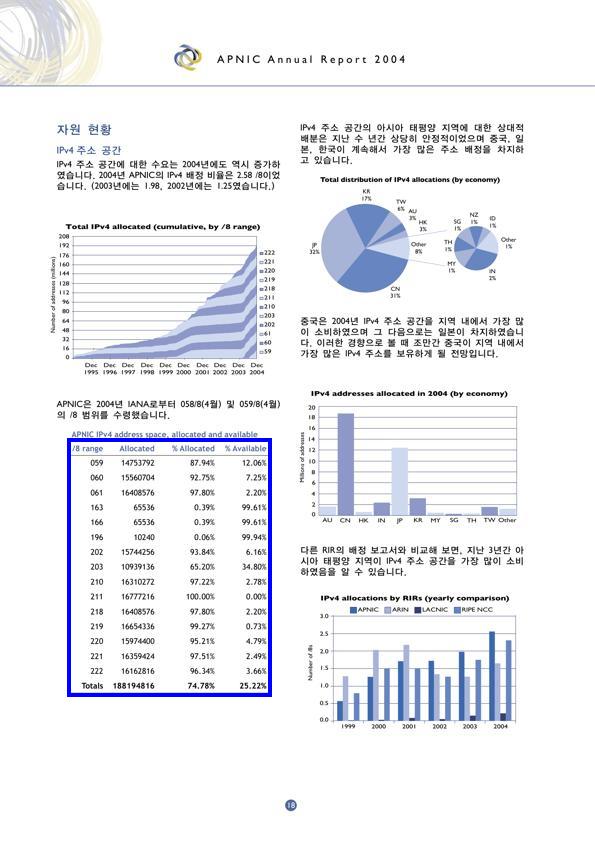

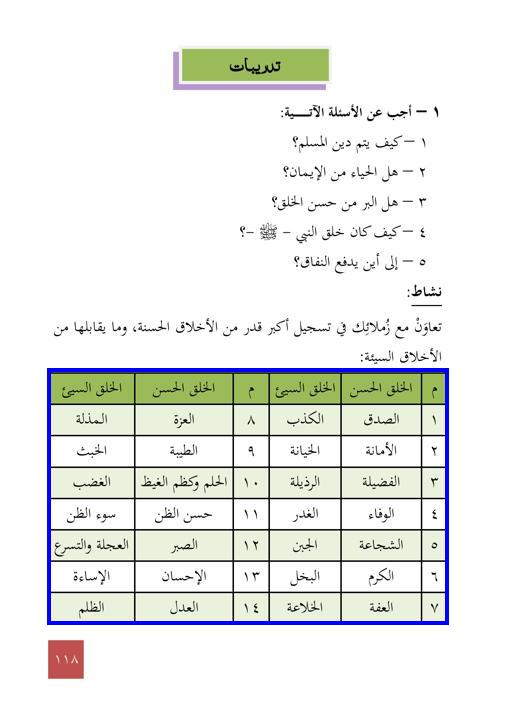
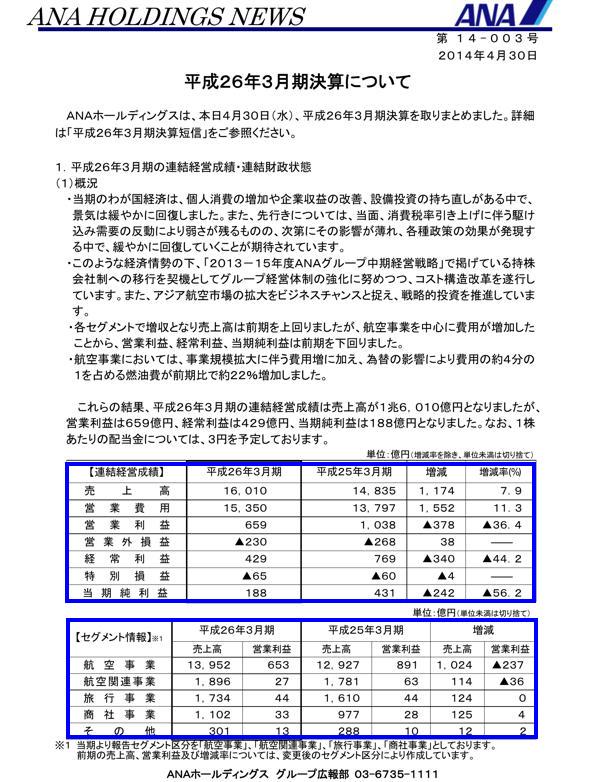



Examples of complex document pages with annotated table bounding boxes with blue colored rectangles across different document formats, types, layouts, and languages.
| Dataset | #Image | #Instance | A.M | Format | Document Type | Language |
|---|---|---|---|---|---|---|
| ICDAR-2013 | 238 | 150 | Manual | PDF, Scanned | Government documents | English |
| ICDAR-2019 | 1,639 | 3,600 | Manual | PDF, Scanned | Books, Scientific journals, Forms, Financial statements | English |
| UNLV | 2,889 | 558 | Manual | Scanned | Technical reports, Magazines,Business letters, Newspapers | English |
| DeepFigures | 5.5M | 1.4M | Automatic | Research articles | English | |
| Marmot | 2000 | 958 | Semi-automatic | Books and Research articles | English, Chinese | |
| TNCR | 6,621 | 9,428 | Semi automatic | PDF, Scanned | - | English |
| STDW | 7,000 | 12,431 | Manual | Invoices, Research papers, Books | English, German,Japanese, Hindi, etc. | |
| ICT-TD | 5000 | - | Manual | ICT commodities | English | |
| TableBank | - | 417,234 | Automatic | Word and LaTeX documents | - | English, Chinese,Japanese, Arabic |
| PubTables-1M | 1M | 948K | Automatic | Scientific articles | English | |
| UniTabBank (ours) | 55,443 | 81,179 | Semi automatic | PDF, Scanned, Photographed | Annual reports, Books, Magazines, Newspapers | 28 languages — English, Arabic, Urdu, Hindi, etc. |
Shows table detection benchmark datasets along with UniTabBank. A.M. denotes the annotation mechanism.